앙상블 모델
-
앙상블: 조화 또는 통일을 의미
-
어떤 데이터의 값을 예측할 때 여러 개의 모델을 조화롭게 학습시켜 그 모델의 예측 결과치를 이용하는 모델
-
여러 개의 결정 트리를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신 러닝 기법
-
여러 개의 약 분류기를 결합하여 강 분류기를 만드는 것
-
앙상블 모델의 종류
-
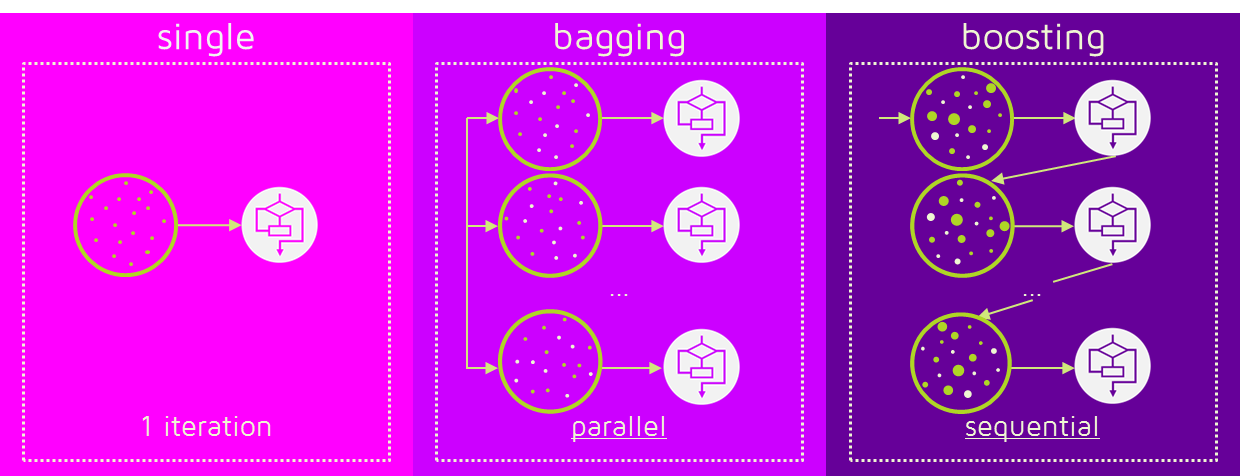
배깅(Bagging; Bootstrap Aggregation):
-
샘플을 여러 개 뽑아 각 모델을 학습 시켜 결과물을 집계하는 방법
-
예를 들어 6개의 독립적인 결정 트리 모델이 있다. 4개는 A로 예측, 2개는 B로 예측했다면 A를 최종 결과로 예측하는 방식(분류 문제)
- 대표적인 예가 랜덤 포레스트
-
-
부스팅(Boosting):
-
가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법
-
처음 모델이 예측하면 그 예측 결과에 따라 데이터에 가중치를 부여하고 다음 모델에 영향을 주는 방식
-
잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만듬
-
오답에 대해 높은 가중치, 정답에 대해 낮은 가중치를 부여 한 번 학습이 모두 끝나면 최종 모델 결과 예측에 영향을 준다.
-
-
부스팅은 배깅에 비해 에러가 적음
-
하지만 부스팅은 속도가 느리고 overfitting 가능성이 있다.
출처: swallow.github.io
-
랜덤포레스트(Random Forest)
- sklearn.emsemble 모듈
-
기본적인 아이디어
-
성능이 좋지 않은 예측기를 여러 개 만들고
-
분류의 경우에는 각 예측기에서 가장 많이 예측된 값으로 예측
-
회귀의 경우에는 각 예측기의 평균으로 예측
-
-
랜덤 포레스트 기본 구현
-
sklearn.model_selection모듈의ShuffleSplit(API)를 이용하여, 무작위로 선택된 100개의 샘플을 각각 갖는 훈련 세트의 서브셋을 1,000개 생성 -
격자탐색을 통해 찾은 하이퍼파라미터를 이용하여 생성한 결정트리 예측기(4.1에서 구한
best_clf이용)를 훈련 세트의 각 서브셋으로 학습시켜 1000개의 약한 분류기를 생성 -
테스트 세트 샘플에 대해 1,000개의 결정 트리 예측을 만들고 다수로 나온 예측을 반환하는 예측기 생성 (
scipy.stats모듈의mode()함수 이용) -
랜덤포레스트 (약한 분류기에 대한 다수 결정) 예측에 대한 정확도 비교
# 랜덤포레스트 기본 구현 (1)
from sklearn.model_selection import ShuffleSplit
n_trees = 1000
n_instances = 100
mini_sets = []
result_split = ShuffleSplit(n_splits=n_trees, test_size=len(X_train) - n_instances, random_state=42)
for mini_train_index, mini_test_index in result_split.split(X_train):
X_mini_train = X_train[mini_train_index]
y_mini_train = y_train[mini_train_index]
mini_sets.append((X_mini_train, y_mini_train))
#무작위로 분할하여 1000개 서브셋 생성
# 랜덤포레스트 기본 구현 (2)
from sklearn.base import clone
forest = [clone(best_clf) for _ in range(n_trees)]
accuracy_scores = []
for tree, (X_mini_train, y_mini_train) in zip(forest, mini_sets):
tree.fit(X_mini_train, y_mini_train)
y_pred = tree.predict(X_test)
accuracy_scores.append(accuracy_score(y_test, y_pred))
print(f"1000개의 약한 학습기에 대한 정확도 평균:{np.mean(accuracy_scores)}\n")
#1000개의 약한 학습기에 대한 정확도 평균:0.856837
랜덤포레스트 기본 구현 (3)
Y_pred = np.empty([n_trees, len(X_test)], dtype=np.uint8)
for tree_index, tree in enumerate(forest):
Y_pred[tree_index] = tree.predict(X_test)
from scipy.stats import mode
y_pred_votes, n_votes = mode(Y_pred, axis=0)# 랜덤포레스트 기본 구현 (4)
print(f"격자탐색 결정트리의 테스트 데이터셋 예측 정확도: {accuracy_score(y_test, y_pred3)}")
print(f"랜덤포레스트의 테스트 데이터셋 예측 정확도: {accuracy_score(y_test, y_pred_votes.reshape([-1]))}"격자탐색 결정트리의 테스트 데이터셋 예측 정확도: 0.9156666666666666)
#격자탐색 결정트리의 테스트 데이터셋 예측 정확도: 0.9156666666666666
#랜덤포레스트의 테스트 데이터셋 예측 정확도: 0.9166666666666666
Reference:
-
기계학습_하길찬 교수님 수업을 듣고 공부한 내용입니다.